




Vector Dot product in CUDA C; CUDA C Program for Vector Dot product
Before start reading,
one should know everything about Vector Dot Product. So, I Prefer you guys please
go through any of the link so you better understands code
Reference:
Before reading further,
I advise u to go through this article so you more familiar with coding
style. Please go through the explanation and come back to this article.
We divide this article in two part. Part1 will describe everything
how we come to the code and Part2 will list code and more explanation
regarding threads and blocks.
Let’s start discussion
on Dot Product.
Unlike vector addition, dot product is a reduction from vectors to a scalar.
c = a ∙ b
c = (a0, a1, a2, a3) ∙ (b0, b1, b2, b3)
c = a0 b0 + a1 b1 + a2 b2 + a3 b3
For example, if we take the dot
product of two four-element vectors, we would get
Equation 1.
Equation
1
(x1,
x2, x3, x4). (y1, y2, y3, y4) = x1y1 + x2y2 +
x3y3 + x4y4
|
Perhaps the algorithm we tend to use
is becoming obvious. We can do the first step exactly how we did vector
addition. Each thread multiplies a pair of corresponding entries, and then
every thread moves on to its next pair. Because the result needs to be the sum
of all these pairwise products, each thread keeps
a running sum of the pairs it has
added. Just like in the addition example, the threads increment their indices
by the total number of threads to ensure we don’t miss any elements and don’t
multiply a pair twice. Here is the first step of the dot product routine:
As you can see, we have declared a
buffer of shared memory named cache. This
buffer will be used to store each thread’s running sum. Soon we will see
why we do this, but for now we will simply examine the mechanics by
which we accomplish it. It is trivial to declare a variable to reside in shared
memory, and it is identical to the means by which you declare a variable as
static or volatile in standard C:
__shared__ float cache[threadsPerBlock];
|
We declare the array of size threadsPerBlock
so each thread in the block has a place to store its temporary result. Recall
that when we have allocated memory globally, we allocated enough for every
thread that runs the kernel, or threadsPerBlock times the total number of
blocks. But since the compiler will create a copy of the shared variables for
each block, we need to allocate only enough memory such that each thread in the
block has an entry. After allocating the shared memory, we compute our data
indices much like we have in the past:
int tid
= threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex
= threadIdx.x;
|
The computation for the variable tid
should look familiar by now; we are just combining the block and thread indices
to get a global offset into our input arrays. The offset into our shared memory
cache is simply our thread index. Again, we don’t need to incorporate our block
index into this offset because each block has its own private copy of this
shared memory.
Finally, we clear our shared memory
buffer so that later we will be able to blindly sum the entire array without
worrying whether a particular entry has valid data stored there:
//
set the cache values
cache[cacheIndex]
= temp;
|
It will be possible that not every
entry will be used if the size of the input vectors is not a multiple of the
number of threads per block. In this case, the last block will have some
threads that do nothing and therefore do not write values. Each thread computes
a running sum of the product of corresponding entries in a and b. After
reaching the end of the array, each thread stores its temporary sum into the
shared buffer.
float temp = 0;
while (tid < N)
{
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// set the cache values
cache[cacheIndex] = temp;
|
At this point in the algorithm, we
need to sum all the temporary values we’ve placed in the cache. To do this, we
will need some of the threads to read the values that have been stored there.
However, as we mentioned, this is a potentially dangerous operation. We need a
method to guarantee that all of these
Write’s to the shared array cache[] complete before anyone tries to
read from this buffer. Fortunately, such a method exists:
//
synchronize threads in this block
__syncthreads();
|
This call guarantees that every thread
in the block has completed instructions prior to the __syncthreads() before the hardware will execute the next
instruction on any thread. This is exactly what we need! We now know that when
the first thread executes the first instruction after our __syncthreads(), every other thread in the block has also finished
executing up to the __syncthreads().
Now that we have guaranteed that our temporary cache has been filled, we can
sum the values in it. We call the general process of taking an input array and
performing some computations that produce a smaller array of results a reduction.
Reductions arise often in parallel computing, which leads to the desire to give
them a name.
The naïve way to accomplish this
reduction would be having one thread iterate over the shared memory and
calculate a running sum. This will take us time proportional to the length of
the array. However, since we have hundreds of threads available to do our work,
we can do this reduction in parallel and take time that is proportional to the
logarithm of the length of the array. At first, the following code will look
convoluted; we’ll break it down in a moment.
First, the following code will look
convoluted; we’ll break it down in a moment. The general idea is that each
thread will add two of the values in cache[]
and store the result back to cache[]. Since each thread combines two entries
into one, we complete this step with half as many entries as we started with.
In the next step, we do the same thing on the remaining half. We continue in
this fashion for log2(threadsPerBlock)
steps until we have the sum of every entry in cache[]. For our example, we’re
using 256 threads per block, so it takes 8 iterations of this process to reduce
the 256 entries in cache[] to a
single sum.
The
code for this
follows:
// for reductions, threadsPerBlock must be a power of 2
// because of the following code
int i = blockDim.x/2;
while (i != 0)
{
if
(cacheIndex < i)
cache[cacheIndex] +=
cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
|
For the first step, we start with i as
half the number of threadsPerBlock.
We only want the threads with indices less than this value to do any work, so
we conditionally add two entries of cache[]
if the thread’s index is less than i. We protect our addition within an if(cacheIndex < i) block. Each
thread will take the entry at its index in cache[],
add it to the entry at its index offset by i, and store this sum back to cache[].
Suppose there were eight entries in
cache[] and, as a result, i had the value 4. Shows by Fig. below;
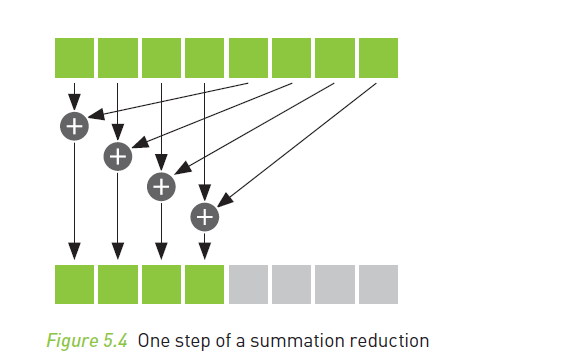
Continue with Part 2
Got Questions?
Feel free to ask me any question because I'd be happy to walk you through step by step!
References
For Contact us….. Click on Contact us Tab




Good info on this post. You have shared very valuable info here.
ReplyDeletec language training
Very clearly explained. It was perfectly clear step-by-step structured. Congratulations on the good work!
ReplyDeleteshame on you for copying and pasting from textbooks and not citing the original source. this whole blog is a copy-paste from blogs or books by reputed authors. F*ing copycat Indians.
ReplyDeleteAnalogica Data is one of best product developement company in india,developing a product means developing a bond with your clients and businesses. The strength of the relationship depends on the functionality and Product Development Service Provider
ReplyDelete.
As the author of the book from whom you copied and pasted this, couldn't copy and paste the attribution as well? So, I guess I have questions about the code/blog, but I'll let my publisher ask them. :)
ReplyDeleteIf you like this post, you'll *love* the book it's stolen from. I highly recommend it: http://amzn.com/0131387685
ReplyDeleteAt any given time that i visit a page, my very first concern is always the kind of content is in it. This is one of the pages that i have found to be very interesting, helpful and very professional. It was great to read, and really i would like to see more of this. You can always be sure if finding the best writing assistance at; Statement Of Purpose Writing Services
ReplyDeleteCreating these articles is at a high level.
ReplyDelete