




Vector Dot product in CUDA C; CUDA C Program for Vector Dot product
We divide this article in two part. Part1, will describe everything how we come to the code and Part2 will list code and more explanation regarding threads and blocks.
Jump to Part 1
Lets Continue our discussion
Part
2
In this part we list all about threads
and block heuristics. If you know basic about Thread and blocks heuristics,
please go through this link
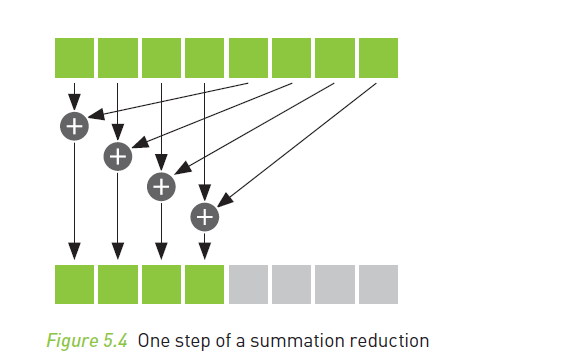
After we have completed a step, we
have the same restriction we did after computing all the pairwise products.
Before we can read the values we just stored in cache[], we need to ensure that every thread that needs to write to
cache[] has already done so. The __syncthreads() after the assignment
ensures this
condition is met.
After termination of this while()
loop, each block has but a single number remaining. This number is sitting in
the first entry of cache[] and is the sum of every pairwise product the threads
in that block computed. We then store this single value to global memory and
end our kernel:
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
|
Why do we do this global store only
for the thread with cacheIndex == 0?
Well, since there is only one number that needs writing to global memory, only
a single thread needs to perform this operation. Conceivably, every thread could perform this
write and the program would still work, but doing so would create an
unnecessarily large amount of memory traffic to write a single value. For
simplicity, we chose the thread with index 0, though you could conceivably have
chosen any cacheIndex to write cache[0] to global memory. Finally,
since each block will write exactly one value to the global array c[], we can simply index it by blockIdx.
We are left with an array c[], each
entry of which contains the sum produced by one of the parallel blocks. The
last step of the dot product is to sum the entries of c[]. Even though the dot
product is not fully computed, we exit the kernel and return control to the
host at this point. But why do we return to the host before the computation is
complete?
Previously, we referred to an
operation like a dot product as a reduction. Roughly speaking, this is
because we produce fewer output data elements than we input. In the case of a
dot product, we always produce exactly one output, regardless of the size of
our input. It turns out that a massively parallel machine like a GPU tends to
waste its resources when performing the last steps of a reduction, since
the size of the data set is so small
at that point; it is hard to utilize 480 arithmetic units to add 32 numbers!
For this reason, we return control to
the host and let the CPU finish the final step of the addition, summing the
array c[]. In a larger application, the GPU would now be free to start another
dot product or work on another large computation.
However, in this example, we are done
with the GPU. In explaining this
example, we broke with tradition and jumped right into the actual kernel
computation. We hope you will have no trouble understanding the
body of main() up to the kernel call,
since it is overwhelmingly similar to what we have shown before.
Final
Words; How we calculate blocks for limited number of threadsperblock
But what if we are given a very short
list and 32 blocks of 256 threads apiece is too many? If we have N data
elements, we need only N threads in order to compute our dot product. So in
this case, we need the smallest multiple of threadsPerBlock that is greater
than or equal to N. We have seen this once before when we were adding vectors.
In this case, we get the smallest multiple of threadsPerBlock that is greater
than or equal to N by computing (N+(threadsPerBlock-1)) / threadsPerBlock. As
you may be able to tell, this is actually a fairly common trick in integer
math, so it is worth digesting this even if you spend most of your time working
outside the CUDA C realm.
Therefore, the number of blocks we
launch should be either 32 or (N+(threadsPerBlock-1)) / threadsPerBlock,
whichever value is smaller.
const int blocksPerGrid =
imin( 32,
(N+threadsPerBlock-1) / threadsPerBlock );
|
If you
found all our explanatory interruptions bothersome, here is the entire source
listing, sans commentary:
#include <iostream>
using namespace std ;
#define min(x,y) (x>y?x:y)
#define N 33*1024
#define ThreadPerBlock 256
//smallest multiple of
threadsPerBlock that is greater than or equal to N
#define blockPerGrid min(32 , (N+ThreadPerBlock-1) /
ThreadPerBlock )
__global__ void Vector_Dot_Product ( const float *V1
, const float *V2
, float *V3 )
{
__shared__ float chache[ThreadPerBlock] ;
float temp ;
const unsigned int tid
= blockDim.x * blockIdx.x + threadIdx.x ;
const unsigned int chacheindex
= threadIdx.x ;
while (
tid < N )
{
temp += V1[tid] * V2[tid] ;
tid += blockDim.x * gridDim.x ;
}
chache[chacheindex] = temp
;
__synchthreads () ;
int i
= blockDim.x / 2 ;
while ( i!=0 )
{
if ( chacheindex < i )
chache[chacheindex] += chache
[chacheindex + i] ;
__synchthreads () ;
i/=2 ;
}
if ( chacheindex == 0 )
V3[blockIdx.x] = chache [0] ;
}
int main ( int argv
, char *argc )
{
float *V1_H
, *V2_H , *V3_H ;
float *V1_D
, *V2_D , *V3_D ;
V1_H = new float [N]
;
V2_H = new float [N]
;
V3_H = new float [blockPerGrid]
;
cudaMalloc ( (void **)&V1_D , N*sizeof(float)) ;
cudaMalloc ( (void **)&V2_D
, N*sizeof(float))
;
cudaMalloc ( (void **)&V3_D
, blockPerGrid*sizeof(float)) ;
for ( int i
= 0 ; i<N ; i++ )
{
V1_H[i] = i ;
V2_H[i] = i*2 ;
}
cudaMemcpy ( V1_D , V1_H ,
N*sizeof(float)
, cudaMemcpyHostToDevice ) ;
cudaMemcpy ( V2_D , V2_H , N*sizeof(float) ,
cudaMemcpyHostToDevice ) ;
Vector_Dot_Product
<<<blockPerGrid , ThreadPerBlock >>> (V1_D , V2_D , V3_D )
;
cudaMemcpy ( V3_H , V3_D , N*sizeof(float) ,
cudaMemcpyDeviceToHost ) ;
cout <<"\n Vector Dot Prodcut is : " ;
float sum
= 0 ;
for ( int i = 0 ; i<blockPerGrid ; i++ )
sum+=V3_H[i] ;
cout << sum << endl ;
cudaFree ( V1_D) ;
cudaFree ( V2_D) ;
cudaFree ( V3_D) ;
delete [] V1_H ;
delete []
V2_H ;
delete []
V3_H ;
}
|
Got Questions?
Feel free to ask me any
question because I'd be happy to walk you through step by step!
References
For Contact us….. Click on Contact us Tab




This comment has been removed by the author.
ReplyDeleteThank you for your article, which is great. Your explanation is neat. nevertheless, your code does not compile: spelling and common mistakes. Here is a working version (I also added a line to check the result):
ReplyDelete#include
using namespace std;
#define min(x,y)(x>>(V1_D , V2_D , V3_D );
cudaMemcpy( V3_H , V3_D , blockPerGrid*sizeof(float) , cudaMemcpyDeviceToHost );
cout <<"\n Vector Dot Product is : ";
float sum = 0;
for( int i = 0; i < blockPerGrid; i++ )
sum += V3_H[i];
cout << sum << endl;
cudaFree(V1_D);
cudaFree(V2_D);
cudaFree(V3_D);
cout << " with the cpu " << cpuDot;
delete[] V1_H;
delete[] V2_H;
delete[] V3_H;
return 0;
}
Ok, I tried. It seems my code is truncated after I press "publish"... Sorry. The main mistakes are:
Delete- #define min is incorrect
- it is __syncthreads() and not __synchthreads()
- V3_X has a dimension of blockPerGrid, so you must replace the N by "blockPerGrid" in the cudaMemcpy
as she said there is an error on __synchthread()
ReplyDeleteand also error in tid += blockDim.x * gridDim.x ; (line no:27)how to correct this??
The code is explained very nicely. I was trying to modify the code so that It also works with 2D blocks and grids. Unfortunately my code didn't work. I was wondering if you have this code for 2D blocks and grids.
ReplyDeleteRegards
Its perplexing the I couldn't find a proper code for reduction using 2D blocks and grids. There's one here but its highly inefficient using repeated kernel launch and memcpy's in a while loop. The so called 'experts' keep posting codes for 1D blocks and grids. In real world there happens to be instances where launch a single 2D grid and block kernel and perform multiple functions with it.
Deletehttp://stackoverflow.com/questions/25415239/cuda-sum-of-all-elements-in-array-using-linearized-2d-shared-memory
Alright here's the indexing used if reduction kernel is launched using 2D grids and block. Note: This is based on Reduction method #7 by Mark Harris here http://developer.download.nvidia.com/assets/cuda/files/reduction.pdf.
DeleteJust replace the indexing in the manual with this
//global indexing
int idx_in = blockSize * ( (blockIdx.y*gridDim.x + blockIdx.x )* 2) + ((threadIdx.y * blockDim.x) + threadIdx.x);
//shared memory indexing
int idx_temp = threadIdx.y * blockDim.x + threadIdx.x;
//gridsize value
unsigned int gridSize = gridDim.y * gridDim.x * blockSize * 2;
You copied the text of my book, maybe if you had copied the code a little better... if you want code that works, the original text, etc, why not get a copy of the book the text was copied from? :) The code is downloadable from NVIDIA directly, and I believe is currently free (under some license), but it is all there and accurate.
ReplyDelete#define min(x,y) (x>y?x:y) isn't this a max function?
ReplyDeleteVery interesting is what you write.
ReplyDeleteline 28 error: expression must be a modifiable lvalue
ReplyDelete